
LLMs Architectures Today and Tomorrow

A common question today, right after “What is an LLM?”, is “How are they used?”. That is, what is the current architecture for what IT calls deployment? Initially, and still for many customers, this architecture is a big, static Large Language Model (LLM) in the cloud (think ChatGPT, Bard, Bing, Claude) that is fed a text prompt, either directly in a chat interface or through an API call. However, changes are underway. What is coming next?
Today’s LLM Architectures
As noted in my article describing the Institutional->Individual->Invisible model of technology deployment, we are currently in the Institutional phase of LLM deployment. Producing and running an LLM is very expensive, so only institutions with access to large amounts of capital and expertise can accomplish this. LLMs are created by writing code to implement the model and then “training” the model using representative data called, imaginatively, training data. Today, creating an LLM is where most of the expense accrues.
Training the model is very costly because the amount of training data is, as my kids say, ginormous and the cost of computing (usually GPUs) required to train the model is measured in the millions to tens or even hundreds of millions of dollars. As a result, LLMs are not trained “from scratch” very often, leaving them unaware of any data outside of the training data (and thus ignorant of current events). Adding new training to current LLMs can also be expensive, and may not be allowed by the LLM vendor. Further, adding new data to the total training data for the LLM may be undesirable or illegal for sensitive or proprietary data.
When ChatGPT 3.5 was released, the reaction was “It’s incredible what can already be accomplished”. Soon, however, there was desire for inclusion of current events and data more specific to a task, e. g. a set of repair documents for a service organization. Because of the expense and challenges of updating the LLM, these more dynamic elements were rapidly added via changes to the architecture via plugins, or in the case of Microsoft, by integrating Open AI’s ChatGPT into Bing search and Azure cloud APIs. Google responded by adding LLM capabilities to its search, calling it Bard.

The desire to use LLMs in conjunction with sensitive or proprietary data is met today by adding “context” to the prompt. Context can be thought of as a more complex prompt including lots more data. Increasing context can be done by adding documents right into the prompt text using cut and paste, but LLMs generally limit the amount of total text allowed in the prompt (technically the LLM vendors limit tokens which is not exactly the same but close enough for this discussion), and large text inputs can dramatically slow down the LLM response. Also, while most LLMs today will offer to keep all the text in the prompt isolated and not added to the total training data for the LLM, verification is imperative.
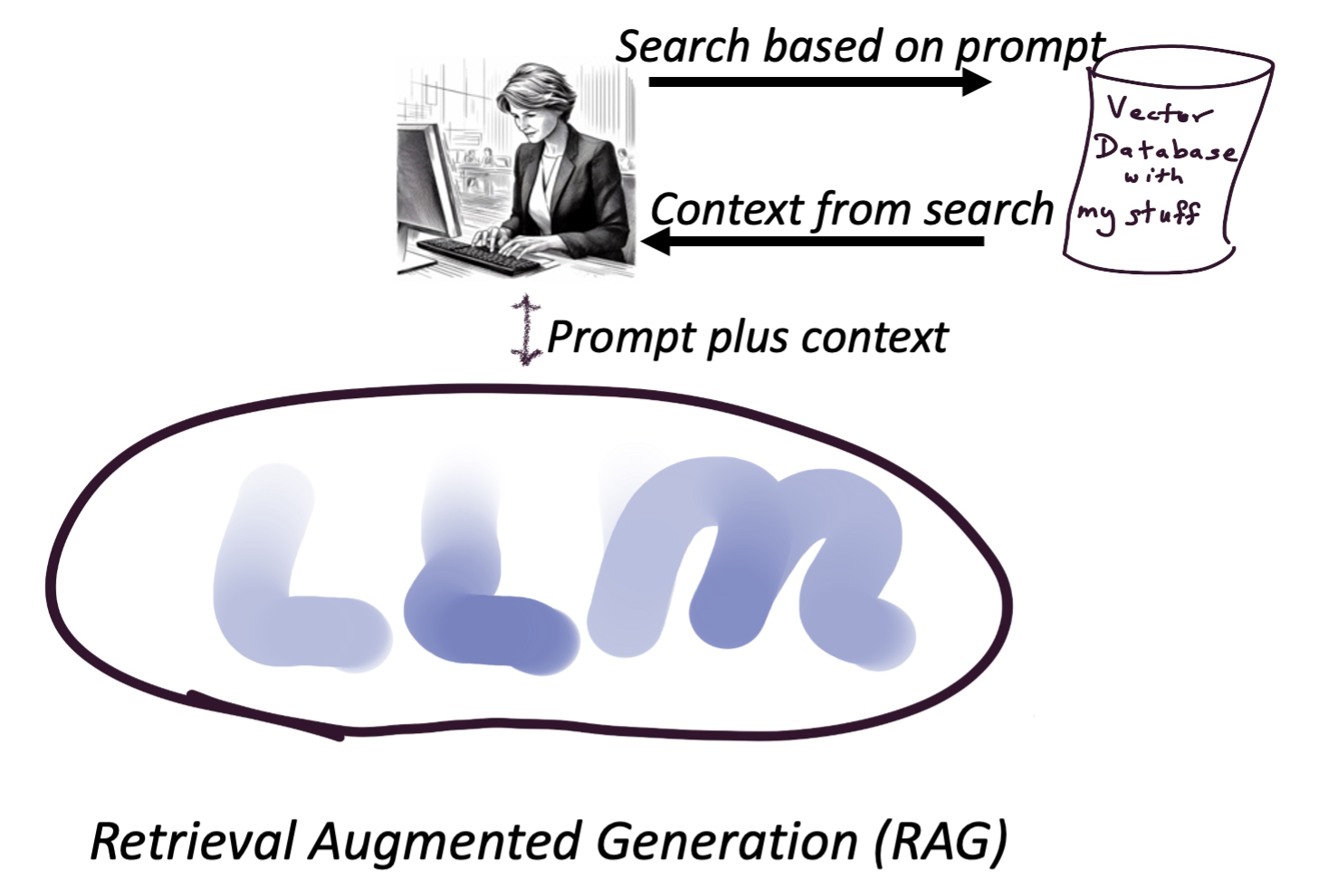
For many customers, the amount of data to be added is too large to be used in the prompt context, or the response time is too slow. To address this, Retrieval Augmented Generation (RAG – who comes up with these acronyms?) is being deployed by many customers. RAG architecture adds a component called a vector database, where the customer specific data is entered in a special format that enables rapid search for data relevant to a specific prompt. This data is significantly smaller and can be further limited, if necessary, to fit into the prompt context and passed to the LLM. (NB The creators of RAG told me that this isn’t really RAG as described in the paper they wrote, but the name has been widely used so what are you going to do? Alan Kay, the inventor of Object-Oriented Programming had a similar experience. He said many times that most use of C++/Java is not object-oriented but couldn’t stop the “kidnapping” of the term).
What's next
I will offer my viewpoint on the very short term (3-12 months) because this is nearly certain. I’ll address the longer term in another article. Consider that all the above architectures have been deployed within the last year. These rapid changes will continue as the use of LLMs broadens and deepens. In the short term, RAG will continue to grow, because it is showing success in enabling customers to take advantage of LLM capabilities on their own data while keeping that specific data out of the LLM and in a secure location (“behind the firewall” is the phrase often used).
Another short-term development will be the addition of open-source and proprietary LLMs as significant new competitors. These will be primarily deployed using the RAG architecture. These newer LLMs will focus on performance by creating much smaller models that are considerably less expensive to create and maintain. Two types of new LLMs are in late stages of development or already on the market. First, there are general purpose LLMs that achieve similar performance to the current offerings using much smaller models (Mistral, Llama2). The second type will focus on more specific use cases, limiting the size of the model. For example, focusing on a specific industry (retail pharmacy) or function (customer service).
A very short term evolution will be the addition of what are referred to as multimodal capabilities. In plain English, products will start to integrate the ability to deal with more than text. They will generate images and videos as well. My colleague John Sviokla has referred to these models as Large Media Models (LMMs) rather than Large Language Models (LLMs). Whatever the name, the products will begin to deal with all forms of media.
Wildcards
Wildcards are unexpected developments that can change the course of an industry, and in this case, change the deployment architecture for LLMs. A very short-term wildcard is model routers (Martian) that connect customers to a variety of LLMs. There are already several well-known LLMs from the very large tech companies, and literally hundreds of thousands from smaller companies. New start-ups are promising they can route a request to the best model for that particular prompt. This makes sense, but the results are not in yet.
A short-term to medium-term wildcard is the development of new algorithms that supplant the current models' algorithms. Or modifications of the current algorithms that have order of magnitude impacts on performance or a result quality (e.g. MIT’s liquid neural networks, LLM Model Bug?).
In conclusion, the market will continue to evolve rapidly with RAG architecture taking center stage in the short run. New developments will appear almost daily. It will be a wild ride for the foreseeable future.